![]()

 差评
差评老黄出手,从微软手里买下了 Xbox,下一代的 Xbox 将有双显卡、 AI 加持,誓要把隔壁的 PS6 锤出人中黄来。
今天凌晨的时候,小发给我发了个大新闻:
老黄出手,从微软手里买下了 Xbox,下一代的 Xbox 将有双显卡、 AI 加持,誓要把隔壁的 PS6 锤出人中黄来。

但很不幸,这是一个拙劣的愚人节恶搞!
我就说嘛,已经是 AI 军火商的老黄,早就把游戏佬们当成牛夫人了,怎么可能花大价钱再来搞游戏。
还记得前不久的 GTC 大会吧,老黄公布 B200 时的状态,可比发布什么 “ 破 4090 ” 嗨多了。
想买老黄显卡的人,从这里排到了法国。
但,就从世超看来,老黄还真不一定高枕无忧,至少它的脖子被韩国人狠狠卡着。

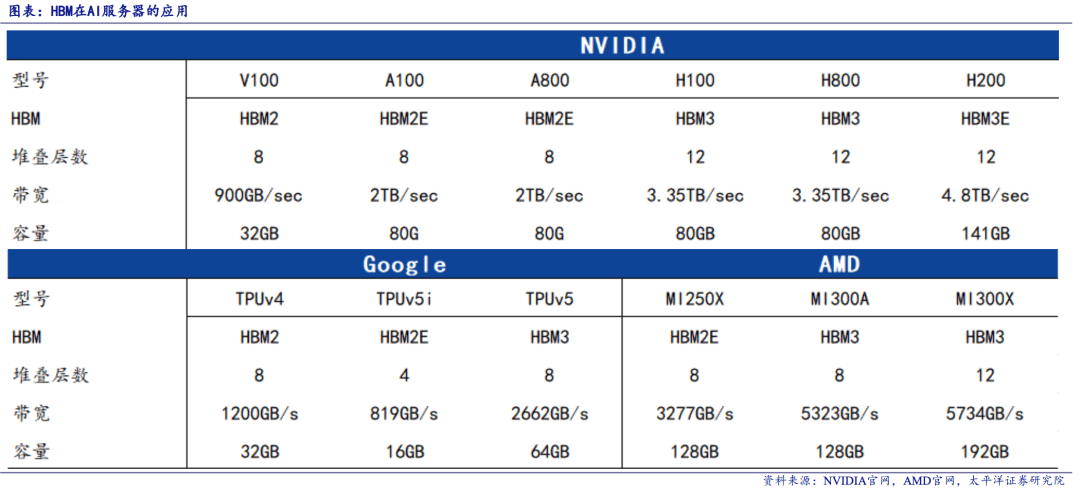
例如老黄最新发布的 B200 芯片上,就有多达 4 叠最新的 HBM ( 高带宽内存 )内存芯片:HBM3e 。
而这个东西,在这个星球上,目前基本上只有韩国人能量产。

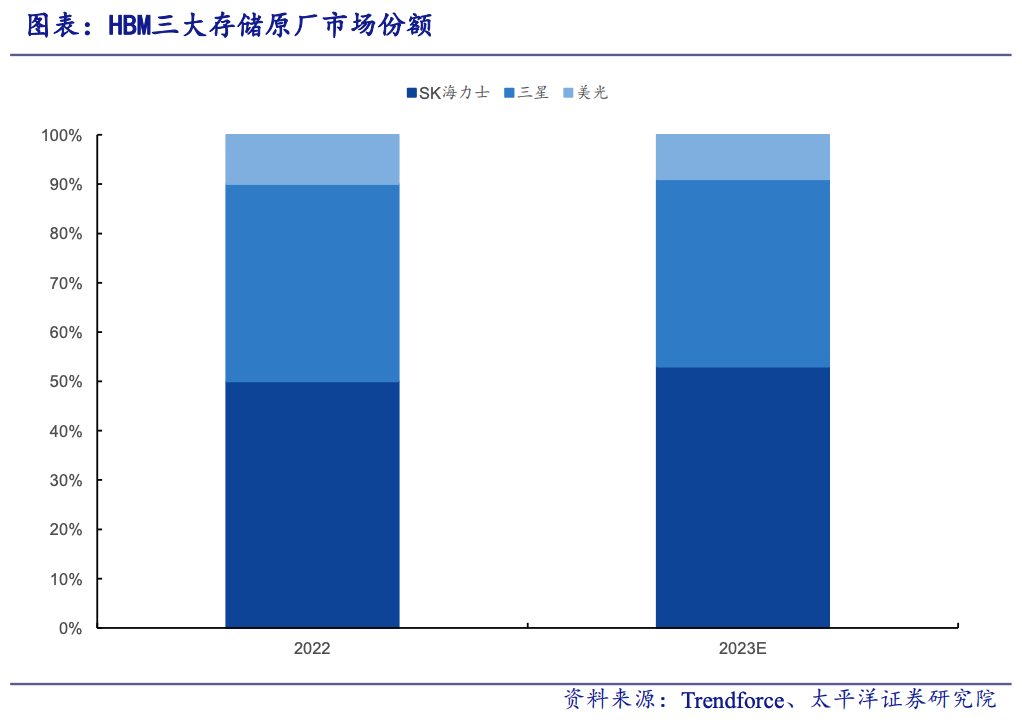
根据 Trendforce 数据,韩国的 SK 海力士和三星,他俩在 2023 年拿捏了全球 90% 的 HBM 内存产能。
而两年市面上的 AI 芯片,什么 A100 A800 们,反正你能想到的,基本就没谁能离开 HBM 内存。
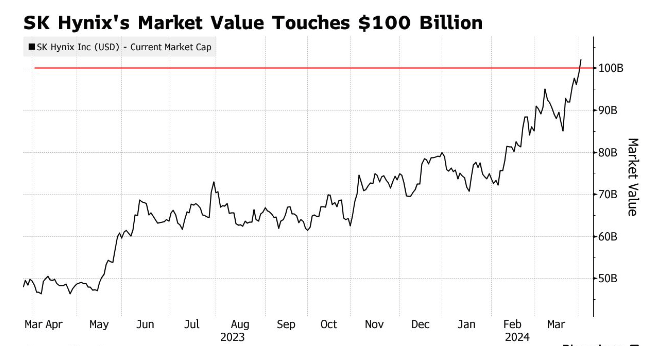
所以,就在老黄的英伟达市值突破万亿的时候, SK 海力士的股价,也在去年偷偷翻了一倍多,如今市值已经突破千亿了。。。
就连之前路线选择错误的三星,股价也涨到了近两年最高的水平。
可能大家对 HBM 内存技术有多重要还没概念。
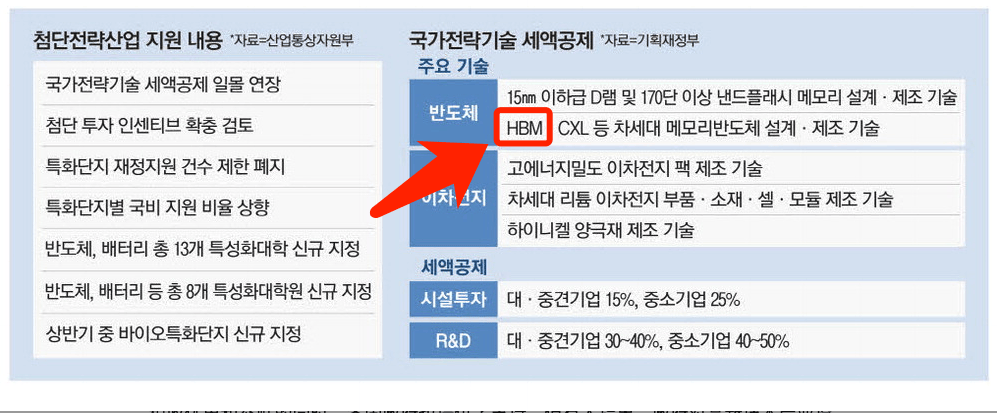
就这么说吧,韩国在今年初已经把这个技术列为国家战略技术,想通过给 SK 海力士和三星税收等方面的优惠,保持着自家的领先地位。
甚至老黄在最新发布的 B200 AI 芯片的同时,早就给了 SK 海力士等几百亿人民币定金,直接把这些厂今年一年的产量给包圆了。
要知道, SK 海力士上个月底刚实现量产交付 HBM3e 内存,这不比隔壁小米 SU7 的大定猛多了?

而这么爽快的生意,可把隔壁三星馋坏了,急急忙忙在 2 月份发布了自家 HBM3e 样品,立马就发给满世界客户验货。

那为什么 HBM 内存能这么受欢迎呢?
这就不得不提内存技术长期以来的拉跨了。
在信息化时代,无论是游戏还是工作,电脑系统的运行速度其实是要靠处理器和内存的互相配合的。
理论上,如果这俩速度接近,那肯定是最佳拍档。

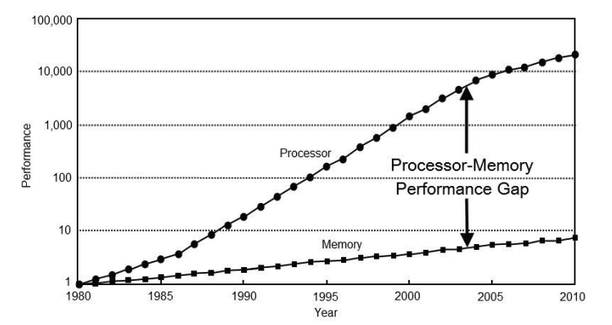
但过去的很长时间里,处理器的性能指数式暴涨,内存和硬件之间的传输速度,却压根就跟不上。
在过去 20 年中,硬件的峰值计算能力增加了90000 倍,但是内存和硬件互连带宽却只是提高了30 倍。
打个不是很贴切的比方,处理器相当于是中华小当家,内存就是边上配菜的助手,小当家技术再高,助手菜配不过来,上菜还是快不了。
所以这些年,内存成了拖累计算机性能的拖油瓶,甚至有人把这种现象称为 “ 内存墙 ” 。
这些问题对于我们臭打游戏的来说,还算能接受,毕竟现在用着 1066 打 3A 的人肯定还不少。
真让他们忙不过来的,其实是这两年的 AI 大爆发。因为 AI 大模型的基础离不开海量的数据和算力,而要想支撑这么大的数据处理和传输,就要打破 “ 内存墙 ” 。
换句话说,打游戏对于小当家来说是点了四菜一汤,那隔壁 AI 随便搞个训练就相当于是要了一桌满汉全席。
所以对于 AI 大厂们来说,内存墙就像是锁死自己发展水平的智子,而 HBM 就是那个破墙者。
和传统的 DDR 内存采用的 " 平房设计 " 不同,破墙者 HBM 采用了 " 楼房设计 " ,来了个降维打击。
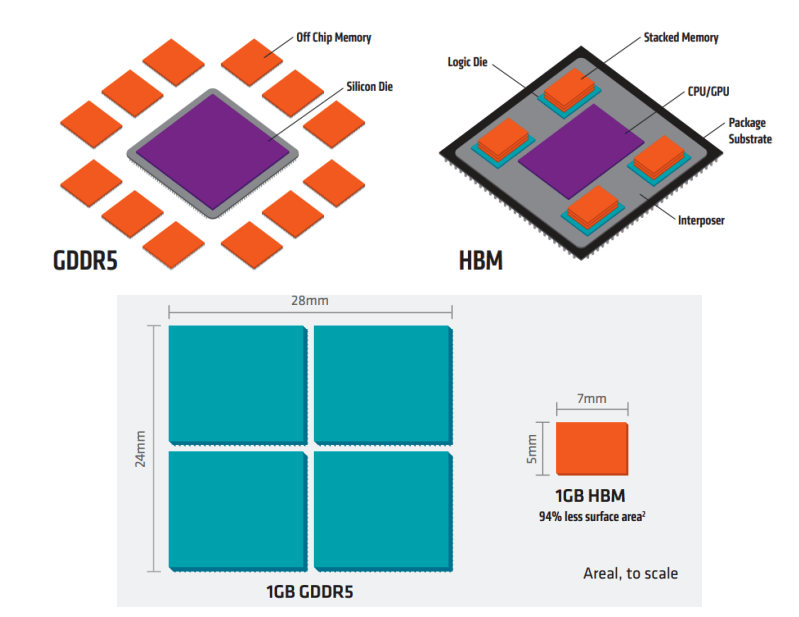
在芯片里造楼,主要靠的是硅通孔( Through-Silicon Via , TSV )这种先进封装技术。
简单来说,就是把不同的芯片叠在一起,中间打一堆孔,然后用铜管等导电物质给接起来。

从物理意义上减小了数据传输距离、占地面积等等。
这样一来,就能减小信号延迟、实现芯片的低功耗、增加带宽等等一堆优点。
随着工艺水平提升, TSV 可以越做越小,密度越来越大,堆叠 Die 层数也能越来越多,就能进一步提升带宽和传输速度以及最大容量。
前面提到三星最新产品,就已经是 12 层堆栈容量高达 36 GB 的 HBM3e 了。
别看说起来这么简单,实际上, HBM 技术里从材料、设计、封装、散热等等环节,都是难点。
而这些技术难点,大部分都是被韩国的 SK 海力士率先攻克的。
所以,像 HBM3 和 HBM3e 也都是由 SK 海力士率先突破并实现量产。
到了 HBM3 这一代,就已经实现了高达 1024 位的数据路径,运行速率也达到了惊人的 6.4 Gb/s ,带宽高达 819 Gb/s 。
而最新的 HBM3e ,其实是 HBM 内存技术家族的第五代产品,它的最高数据处理速度已经达到了每秒 1.18TB (太字节),相当于 1 秒内处理 200 多部全高清( FHD )级别的电影。
别看 HBM 赛道目前还有 SK 海力士、三星和美光御三家在玩,但无论是从发展时间、技术突破还是量产速度上, SK 海力士一直独占鳌头,光他们一家就占领了一半左右的市场份额。
排在身后的,则是同为韩国企业的三星,这家伙今年又一口气组建了两个 HBM 团队想要追赶上进度。
而美国的美光虽然放出话来,自家跳过研发 HBM3 ,直接成功完成了 HBM3e 的研究。
甚至如今还成为了英伟达的供货商之一,但世超觉得,这么大的口气,还有待市场验证。
所以,这么捋下来,英伟达的 AI 军火商计划,还真得建立在这些 HBM 厂商的供货上。
虽然大家都在说, AI 界硬通货是 H100 、是 B200 。
谁能想到,最终居然还被韩国卡着一道呢?
撰文:八戒 编辑:江江 & 面线 封面:焕妍
图片、资料来源:
太平洋证券:AI服务器催化HBM需求爆发,核心工艺变化带来供给端增量 —算力系列报告(一)
东方财富证券:玻璃通孔(TGV)为硅通孔(TSV)有效补 充,AI+Chiplet趋势下大有可为
中邮证券:先进封装关键技术——TSV 研究框架
Micron:Micron Commences Volume Production of Industry-Leading HBM3E Solution to Accelerate the Growth of AI
SK hynix:SK hynix Develops World's Best Performing HBM3E, Provides Samples to Customer for Performance Evaluation
Samsung:Samsung Develops Industry-First 36GB HBM3E 12H DRAM
NVIDIA:NVIDIA DGX B200
半导体产业纵横:HBM3E起飞,冲锋战鼓已然擂响
华尔街见闻:高盛谈HBM:四年十倍的市场,海力士将占据过半份额,美光或后来居上



