![]()

 脑极体
脑极体械曾经让这个世界上的很多技艺濒临灭绝,而如今算法的出现,或许可以做出些许补救吧。
有关于人工智能到底有多强大这件事,已经不用再做过多讨论了。阿尔法狗如何在围棋盘上吊打人类,或者prisma如何模仿出大师的画作,这些案例我们已经见了太多。
不过我更关心的是,什么时候我家的扫地机器人可以不那么弱智,别再咬着地上的数据线不放?
这是一个很普遍的状况:人工智能面对单纯环境中的计算问题、数据处理问题都可以表现的很好,可放到现实生活环境中却是举步维艰。很多实验室连机械手臂抓举杂物这件事都没能突破。
如何让机器人干点实事?
为了能让机器人们做点实事,我们想了很多办法。比如用SLAM(即时定位与地图构建)系统把机器人所在的整个区域构建成一个地图,让它们以计算的方式实现自主移动。又比如利用强化学习,为机器人的正确行为设置奖励。或者是利用迁移学习,在仿真环境中训练程序,再迁移到真实的机器人“脑”中。
这样做的结果,或许可以让工业生产线上的机械手臂更好的工作。可对于日常生活中的大部分场景而言,没有固定不变的地图,没有可以设置奖惩的规则,更没有可以完美仿真的环境。
更何况,以上这些做法,需要数据、大量的数据,以及无尽的训练……
不过,近期伯克利分校在博客上展示了一段视频,是一个小机器人在铺床。而实现这一行为的方式,是通过目前一种更为前沿的方式“Imitation Learning”模仿学习。
模仿学习:现在就开启你的机器人学徒
何谓模仿学习?简单来说,模仿学习是通过在某种意义上模仿人类行为,从而教会智能体如何像人类一样与世界进行交互。
实际上在机器人学习(这里专指实体机器人)这件事上,专家们一直在向一个方向发展:用端到端神经网络实现控制,让机器人不需要编程就可以自行动作。

那么具体怎么做?坦白讲,目前模仿学习还处在Paper大战中,每过三五个月有可能出现一种较新的训练方式,但我们可以提出一些目前属于“共识”类的概念。
首先,模仿学习对于人类来说,可能就是看看别人是怎么做的,然后自己再照着来。而机器人模仿的对象,则是一串动作序列。在模仿学习术语中,被称作专家动作序列。
目前较为公认的做法是,为了贴合强化学习中非常好用的“奖励”概念,把生成对抗神经网络(GAN)引入模仿学习,以生成模型生成机器人自己的动作序列,再用判别模型和专家序列做比对,比对而来的结果就和强化学习中的“奖励”概念一样,这样机器人的动作序列就会和人类的专家序列越来越像。
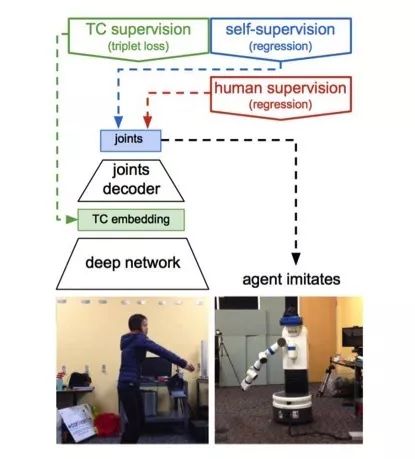
至于如何提取专家动作序列,则和我们分析运动员的动作有些类似。把上帝式的第三人称视角和可以观察到运动主体四周状况的分而论之。可以录制第三人称视角的运动视频,一帧帧的把动作进行聚类,把图像输入到网络,再到机器人的动作关节。又或者把第三人称视角转变成第一人称视角,再将图像信号映射到神经网络之中等等。
总之,目前DeepMind、OpenAI等等机构都在研究模仿学习,我们看到的还仅仅是冰山一角而已。
如何更好的适应现实场景?
On-Policy或许是个办法
这次伯克利展示的铺床机器人,研究重点在于对机器人动作的纠错。
在现实生活中,机器人在服务人类时不可能总有监工相伴,而模仿学习的训练也不可能让机器人永远万无一失。
而解决办法是,使用On-Policy——一边学习一边产生样本的训练方式,为专家序列中加入噪声,从而提高鲁棒性并且可以为机器示范如何纠正错误动作。
就好像故意误导机器人,让它不小心把枕头掉在地上,再教导它这时应该把枕头捡起来。这样在现实场景中,机器人就会知道枕头掉在地上时应该做些什么了。
如果没有这种解决方法,那么可能出现的情况就是,机器人正在铺床,结果枕头不小心掉在了地上,机器人立刻陷入了痴呆状态,不知道该如何继续。又或者,工作人员录下几百部花样丢枕头再捡起来、床单反了再正过来等等“犯错+修正”的示范视频,转换成专家动作序列再让机器人学习。
相比之下,On-Policy实在是太具性价比了。
更少、更少的数据
其实从此前介绍过的阿尔法元和今天的模仿学习,我们似乎能找到一些共同点:算法技术的发展,正在朝计算量越来越小、训练数据越来越少的方向发展。
其中的必然性也很简单,庞大的计算量意味高昂的成本,和人工智能的普及性相悖。至于训练数据,我们要承认,现实生活就是一个庞大的随机场,很多情况是不能提前通过数据训练的。

而以模仿学习为代表的一系列前沿算法,最终发展目标就是Few shot learning、One shot learning甚至Zero shot learning——用尽量少的样本、一个样本甚至无样本来完成训练。
在未来,只需一部铺床叠被的视频,机器人就立刻能在酒店里上岗。不过从当前的发展情况来看,未来恐怕还有点遥远。
但在我来看,把模仿学习应用到抢劳动力饭碗这件事上,意义似乎不大。模仿学习需要训练样本少这一特征,应该被应用于那些真正意义上“样本少”的事情汇中。
比如,那些技艺濒临失传的民间手工艺。当年轻人不愿留在村子里,花费一辈子的时间学习如何做油纸伞、编竹筐时,拍摄下一两部视频、记录下一些参数,就可以让机器人成为这些技艺的传承者。
机械曾经让这个世界上的很多技艺濒临灭绝,而如今算法的出现,或许可以做出些许补救吧。



